


Özet
Gündelik hayatımızda birçok işimizi internet üzerinden online olarak halledebilmekteyiz. İnternet üzerinden derslere girebiliyoruz, yemek sipariş edebiliyoruz, haberleri takip edebiliyoruz. İstediğimiz bilgiye arama motorları sayesinde ulaşabiliyor, akıllı saatler ile uyuduğunuz, uyku kaliteniz, nabız aralığınız, aktivitelerinizi kaydedebiliyor ve görüntüleyebiliyorsunuz. Neredeyse 24 saat içerisinde yaptığımız birçok aktivite kaydedilebiliyor. Bu kayıtlar ise büyük bir veri havuzu oluşturmakta. Bu veri havuzu ile yani popüler adı ile büyük veri sayesinde, kitlelerin ve bireylerin politik görüşlerini, harcama alışkanlıklarını, sağlık durumlarını, ekonomik trendleri ve benzeri birçok olayı önceden tahminlememize, bireyleri ise toplam popülasyon içerisinde sınıflandırmamıza olanak veriyor. Sizin internetteki alışverişlerinizden, gün içerisindeki aktivitelerinize veya sosyal medyadaki beğenileriz yardımı ile psikolojik durumunuz ve hatta cinsel eğiliminiz bile algoritmalar tarafından büyük başarı oranları ile tahminlenebiliyor. Kısacası tek başına anlamsız olan bu kadar veri birleştiğinde sizi ve kitleleri anlamlandırmak ve hatta yönlendirmek için kullanılabilir. Bu da büyük veriyi korunması, işlenmesi ve anlamlandırılması gereken stratejik bir kaynak haline getirmektir. Devletler, kamu kurumları, siyasi partiler, üniversiteler, sivil toplum kuruluşları, özel sektör kurumları, şirketler ve artan şekilde pek çok organizasyon büyük veri çalışmalarının önemini anlıyor. Ancak, pek çoğu hala neyi nasıl yapacağı konusunda ciddi bir ilerleme kaydetmiş değiller. Türkiye’de büyük veriyi saklamak konusunda yasalar çıkarıyor, ama asıl önemli olan büyük veriyi işlemek. Büyük veriyi toplayacak ve işleyecek kurum ve insan kaynaklarının gelişmesini sağlamak daha önemli, yönetim kapasitesini arttırmanın ve sağlamlaştırmanın temellerinden birisi de buradan geçiyor. Bu konuda eksikler çok. Yoksa büyük veri, yer altında işlenmemiş madenler gibi hiçbir işe yaramadan kalır.
Giriş
Büyük veri (big data) tam olarak nedir? Büyük veri, boyutu veya türü, geleneksel, ilişkisel veri tabanlarının verileri düşük gecikmeyle yakalama, yönetme ve işleme yeteneğinin ötesinde olan veri kümeleri olarak tanımlanabilir. Veri kaynakları, yapay zekâ, mobil cihazlar, sosyal medya ve Nesnelerin İnterneti (akıllı cihazlarınızın birbirleri ile etkileşime geçmesi, örneğin çamaşır makinesini cep telefonunuzdan kontrol etmeniz veya cep telefonu ile evin ışıklarını senkronize etmeniz ve siz eve geldiğinizde bunu cep telefonunun konumundan algılayarak ışıkların yanması Nesnelerin İnterneti olarak adlandırılabilir) tarafından yönlendirildiklerinden dolayı geleneksel verilere göre zamanla daha karmaşık hale gelmektedir. Örnek vermek gerekirse, sensörler, cihazlar, video/ses, ağlar, günlük kayıt dosyaları, işlem uygulamaları, web ve sosyal medyadan kaynaklanan farklı veri türleri vb. bunların çoğu gerçek zamanlı olarak ve çok büyük ölçekte oluşturulmaktadır.

Sosyal medya platformlarında veya internet sitelerinde gezerken size özel kişiselleştirilmiş birçok reklam görürüz. Örneğin bir televizyon almak için araştırma yapıyorsanız, göreceğiniz reklamlar da televizyon reklamları olacaktır. Bu reklamlar, “Büyük Veri”nin nasıl kullanıldığına dair harika örneklerdir. Bunlar genellikle bulunduğunuz sitelere, cinsiyetinize, yaklaşık yaşınıza, yaşadığınız yere ve bir sürü başka değişkene dayalı olarak sadece sizin için seçilirler. Bu veriler, sizinle ve diğer herkesle ilgili büyük verinin bir parçasıdır. Şu şekilde de açıklanabilir, bir reklama her tıkladığınızda veya tıklamadığınızda, bu veriler bir yerde depolanır. Online olarak izlediğiniz her dizi, dizinin içeriği, ne kadar süre izlediğiniz, kredi kartı ile yaptığınız bütün harcamalar, sosyal medya beğenileriniz, gezindiğiniz online siteler, telefondaki konum paylaşımınız açık ise gittiğiniz restoranlar, ortalama araç kullanma süreniz ve benzeri veriler, veri kümelerini oluşturur. Verilerin online toplanmasına alternatif olarak marketlerin size verdiği kartlar üyelik kartları ile sizin alışveriş alışkanlıklarınız ile ilgili veriler toplanır.
Gezegendeki 8 milyarı aşan insanla, her saniye çok sayıda veri oluşturulmaktadır. Başka bir deyişle, var olmanız bile veri oluşturmak için yeterli bir neden haline gelmiştir. Bu gibi sebeplerle o kadar çok veri ortaya çıkmıştır ki buna: “Büyük Veri” denmektedir. Büyük veri analitiği ile nihai olarak daha iyi ve daha hızlı karar verme süreci, gelecekteki sonuçları modelleme ve tahminleme ve gelişmiş bir piyasa istihbaratı elde etmek mümkündür.
Bu yazıda, büyük veri (big data) yıllar içinde nasıl geliştiği, nasıl kullanıldığı, günlük yaşamımıza etkisi ve neden hükümetler ve özel şirketler için stratejik bir kaynak olduğu gibi bazı yönlerini ele alacağız.
Büyük Veri’nin (Big Data) Tarihçesi
Veri toplama, eski uygarlıklar tarafından yiyecek ararken kullanılan çubukların sayısına kadar geriye dönük olarak izlenebilir, ancak büyük verilerin tarihi bundan çok daha sonra başlar. Şimdi bizi bugün olduğumuz yere götüren bazı önemli tarihlerin zaman çizelgesine kısaca bakalım.
1880 – Veri yüklemesinin ilk örneklerinden biri ABD’deki 1880 nüfus sayımı sırasında yaşandı. Hollerith Tablolama Makinesi bu sıralarda icat edildi ve bunun ardından nüfus sayımı verilerinin işlenmesi işi on yıllık emek vermek yerine, bir yılın altına indirildi. Bu şirket 1924 yılıda “International Business Machines” adını aldı ya da hepimizin bildiği adıyla söyleyecek olursak IBM.
1928 – Alman-Avusturyalı mühendis Fritz Pfleumer, dijital verilerin gelecek yüzyılda nasıl saklanacağının yolunu açan bant üzerinde manyetik bir veri depolama yöntemi geliştirdi.
1948 – ABD MIT Üniversitesinde yüksek lisans öğrencisi olan Claude Shannon Bilgi Teorisi geliştirildi ve bu günümüzde yaygın olarak kullanılan bilgi altyapısının temelini oluşturdu.
1970 – IBM’de matematikçi olan Edgar F. Codd, büyük veri tabanlarındaki bilgilere, yapısı veya konumu bilinmeden nasıl erişilebileceğini gösteren bir “ilişkisel veri tabanı” sundu. Bu veri tabanı daha önce sadece uzmanlar veya kapsamlı bilgisayar bilgisine sahip olanlar tarafından kullanılıyordu.
1976 – Malzeme İhtiyaç Planlaması (MIP) sistemlerinin ticari kullanımı, bilgileri organize etmek ve planlamak için geliştirildi ve iş operasyonlarını hızlandırmak için daha yaygın hale getirildi. MIP; işletmelerin malzemeye dayalı yatırımlarını en aza indirerek üretimdeki verimliliği artırmak ve alıcılara yapılan hizmetlerini geliştirmek amacıyla kullandıkları bir yönetim çizelgeleme ve kontrol tekniğidir.
1989 – World Wide Web, Tim Berners-Lee tarafından kuruldu.
2001 – Doug Laney, büyük verinin temel özellikleri haline gelen “Verinin 3 V’si”ni açıklayan bir makale yayımladı. Aynı yıl “Hizmet Olarak Yazılım” terimi ilk kez paylaşıldı.
2005 – Büyük veri kümesi depolaması için açık kaynaklı yazılım çerçevesi olan Hadoop oluşturuldu. Hadoop ile verileri tek bir merkezde depolamak ve işlemek yerine birçok farklı merkezde depolayan ve işleyen, veri güvenliğini artıran ve veri işleme hızı ile veriye erişim hızını artıran programlar topluluğudur.
2007 – “Büyük veri” terimi, Wired’ın “Teorinin Sonu: Veri Tufanı Bilimsel Yöntemi Eski Haline Getirdi” başlıklı makalesinde kitlelere tanıtıldı.
2008 – Bilgisayar bilimi araştırmacılarından oluşan bir ekip (Computing Research Association) (CRA), büyük verilerin şirketlerin ve kuruluşların iş yapma biçimini temelden nasıl değiştirdiğini açıklayan “Büyük Veri Hesaplama: Ticaret, Bilim ve Toplumda Devrimsel Atılımlar Yaratmak” başlıklı makaleyi yayınladı. Bu makalenin özelliği, büyük verinin önemi ile ilgili olarak geniş bir perspektiften, hayatımıza etkilerini ele almasıydı.
2010 – Google CEO’su Eric Schmidt, her iki günde bir, insanların, medeniyetin başlangıcından 2003 yılına kadar yarattıkları boyutta bilgi ürettiklerini ortaya koydu.
2014 – Gittikçe, daha fazla şirket Kurumsal Kaynak Planlama Sistemlerini (KKP) buluta taşımaya başladı. Nesnelerin İnterneti, her gün büyük miktarda birbiri arasında veri ileten tahmini 3,7 milyar bağlı cihazlarla ve sensörlerle birlikte yaygın olarak kullanılmaya başlandı.
2016 – ABD’de Başkan Obama yönetimi, topluma ve ekonomiye doğrudan fayda sağlayacak büyük veri uygulamalarının araştırılmasını ve geliştirilmesini sağlamak için tasarlanmış “Federal Büyük Veri Araştırma ve Stratejik Kalkınma Planı”nı yayınladı.
2017 – IBM araştırması, günlük 2,5 kentilyon bayt verinin oluşturulduğunu ve dünyadaki verilerin %90’ının son iki yılda oluşturulduğunu belirtti.
2018 – Cambridge Analythica’nın Facebook’daki 87 milyon kullanıcının verisini kullanıcı onayı olmadan alması ve bu verilerin dönemin ABD Başkanlık adaylarından Trump’ın seçim kampanyasında kullanması sonrasında veri güvenliği ile ilgili olarak birçok ülke kapsayıcı kanunlar yürürlüğe koymaya başladılar.
Büyük Veri’nin Özellikleri Nelerdir?
Büyük verileri işleyen ve depolayan sistemler, büyük veri analitiği kullanımlarını destekleyen araçlarla birlikte kuruluşlardaki veri yönetimi mimarilerinin ortak bir bileşeni haline gelmiştir. Büyük veri genellikle Üç V olarak tanımlanan üç özellik ile karakterize edilir:
Volume – Hacim
Önemli olan veri miktarı. Büyük verilerle, yüksek hacimli düşük yoğunluklu, yapılandırılmamış verileri işlemeniz gerekmektedir. Bu veriler, Twitter veri akışları, bir web sayfasındaki veya mobil uygulamadaki tıklama akışları veya sensör özellikli ekipman gibi değeri bilinmeyen veriler olabilir. Bazı kuruluşlar için bu, onlarca terabayt veri olabilir. Diğerleri için yüzlerce petabayt olabilir.
Velocity – Hız
Hız, verilerin alındığı ve (belki de) üzerinde işlem yapıldığı hızlı oranıdır. Normalde, en yüksek veri hızı, diske yazılmaya kıyasla doğrudan belleğe akmaktadır. Bazı internet özellikli akıllı ürünler, gerçek zamanlı veya neredeyse gerçek zamanlı olarak çalışır ve gerçek zamanlı değerlendirme ve eylem gerektirmektedir.
Variety – Çeşitlilik
Çeşitlilik, mevcut olan birçok veri türünü ifade etmektedir. Geleneksel veri türleri daha önce yapılandırılmıştı ve ilişkisel bir veritabanına düzgün bir şekilde uyuyordu. Büyük verinin yükselişiyle birlikte veriler yeni yapılandırılmamış veri türleri olarak karşımıza çıkmaktadır. Metin, ses ve video gibi yapılandırılmamış ve yarı yapılandırılmış veri türleri, anlam türetmek ve meta verileri desteklemek için ek ön işleme gerektirmektedir.
Bu özellikler ilk olarak 2001 yılında, daha sonra danışmanlık firması Meta Group Inc.’de analist olan Doug Laney tarafından ortaya koyuldu; Gartner, 2005’te Meta Group’u satın aldıktan sonra bunları daha da popüler hale getirdi. Daha sonra, doğruluk, değer ve değişkenlik dâhil olmak üzere büyük verinin farklı tanımlarına birkaç tane daha yeni V eklendi.
Büyük Verinin Değeri ve Doğruluğu
Son birkaç yılda iki V daha ortaya çıktı: değer ve doğruluk. Verinin içsel değeri mevcuttur. Ancak bu değer keşfedilene kadar bunun hiçbir faydası yoktur. Aynı derecede önemli olan bir soru daha mevcuttur: Verileriniz ne kadar doğru ve bunlara ne kadar güvenebilirsiniz?
Günümüzde büyük veri sermaye haline gelmiştir. Dünyanın en büyük teknoloji şirketlerinden bazılarını ele alalım. Sundukları değerin büyük bir kısmı, daha fazla verimlilik üretmek ve yeni ürünler geliştirmek için sürekli olarak analiz ettikleri verilerinden gelmektedir.
Son dönemlerdeki teknolojik gelişmeler, veri depolama ve bilgi işlem maliyetini katlanarak azaltarak, her zamankinden daha fazla veri depolamayı daha kolay ve daha ucuz hale getirmiştir. Artan büyük veri hacmi artık daha ucuz ve daha erişilebilir olduğundan, daha doğru ve kesin iş kararları vermek mümkündür.
Büyük verilerde değer bulmak, yalnızca onu analiz etmekle ilgili değildir (ki bu tamamen başka bir faydadır). Doğru soruları soran, kalıpları tanıyan, bilinçli varsayımlarda bulunan ve davranışları tahminleyen anlayışlı analistler, iş kullanıcıları ve yöneticiler gerektiren eksiksiz bir keşif sürecidir.

Büyük Veri Hayatımızı Nasıl Etkilemektedir?
Akıllı telefonlar, dizüstü bilgisayarlar ve kişisel bilgisayarlardan önce veriye ulaşmak zordu. Ölçümleri kaydetmek ve saklamak çok zaman ve çaba gerektirmekteydi. Her 10 yılda bir yapılan Amerika Birleşik Devletleri nüfus sayımından elde edilen verilerin toplanması ve bir araya getirilmesi genellikle yaklaşık 10 yıl sürmekteydi. Bilgisayarlar veri toplamak, özetlemek ve depolamak için gereken süreyi kısaltmaya yardımcı olmuştur, ancak veri toplama ve analiz etme gücümüz arttıkça, daha kesin tahminlemeler yapabilmekteyiz.
Bugün kullandığımız şekliyle “Büyük Veri” terimi daha çok John Mashey’e atfedilmektedir. Bu terim 1990’larda bu terimi, verilerle çalışmak için yaygın olarak kullanılan, toplamadan yorumlamaya kadar pek çok şeyin üstesinden gelemeyeceği kadar büyük ve karmaşık verileri tanımlamak için kullanılmıştır. Telefonunuz konumunuzu, kullandığınız uygulamaları ve bunları ne kadar süreyle kullandığınızı kaydeder ve kullandığınız tüm bu uygulamaların her biri sizin hakkınızda kendi verilerini toplar.
Zaman zaman “Nesnelerin İnterneti” olarak da adlandırılan, birbirine bağlı bir dünya yaratmış bulunuyoruz. Veri toplayan ve potansiyel olarak buzdolabınızdan arabanıza, saatinizden ışıklarınıza kadar her şeyle iletişim kurabilen “akıllı” cihazlar ağını düşünün. Ne kadar uyuduğunuzu hesaplayan akıllı saatler ile nüfusun uyuma dinamikleri, stres seviyeleri, yürüme alışkanlıkları ve buna bağlı olarak kalp krizi riskini hesaplamak artık mümkün. Elde edilen veriler ile halkın ne kadar sağlıklı bir yaşam sürdüğünü hesaplayarak sağlık yatırımları ile ilgili daha doğru tahminler yapılabilir. Örneğin bir A ilçesinde yaşayan halk günde on bin adım atıyorsa, diğer B ilçesinde yaşan halk ortalama günde iki bin adım atıyorsa, bu iki grup arasında sağlık ve kilo açısında ciddi farklılıklar olacaktır. Nüfus demografisinin aynı olduğunu varsayarsak, iki bölgeleye yapılacak sağlık yatırımının aynı olması beklenemez. Ama sadece demografik özelliklere bakacak olsaydık, bu sefer iki bölgeye de yapılacak hastane ve doktor sayısı aynı olacaktı. Yürüme istatistiklerine bir de bölgelerde yaşayanların online yemek siparişlerini eklersek yaşayanların yemek yeme alışkanlıklarını da öğrenmeye başlarız. Sağlıklı beslenen bir birey ile hazır yemek yiyen bir birey arasındaki sağlık sorunlarından hiç bahsetmeye bile gerek yok. Buna bir de bölgede satılan sigara sayısını eklersek, sağlık açısından bölgelerin daha iyi bir projeksiyonunu çıkarmaya başlarız. Yani ne kadar çok veri elde edersek tahminlerimiz o kadar kesin olmaya başlıyor.

Bir diğer açıdan bakalım; Facebook beğenileri. Yıllar boyu, bu beğenilerin oldukça işe yaramaz olduğu düşünülüyordu. The Game of Thrones’u, Starbucks’ı veya Bodrum’u seviyor olmanız önemli değil. Böyle şeyleri herkes sever. Ancak, bu bilgi düşündüğünüzden daha açıklayıcıdır. 2013 yılında, Ulusal Bilimler Akademisi Bildiriler Kitabı, Cambridge Üniversitesi’ndeki Psikometri Merkezi’nden bir çalışma yayınladı. Katılımcılar, araştırmacı uygulamasında bir kişilik anketi yapan yaklaşık 58.500 Facebook kullanıcısıydı. Ardından, kullanıcıların “beğenilerini” görüntülemek için izin istendi. Elde edilen bulgularda, “Bireysel özellikler ve nitelikler, kullanıcıların beğeni kayıtlarına dayalı olarak yüksek derecede doğrulukla tahmin edilebilir” sonucu ortaya koyuldu. Facebook beğenileri, cinsel yönelim, etnik köken, dini ve siyasi görüşler, kişilik özellikleri, zekâ, mutluluk, bağımlılık yapıcı madde kullanımı, ebeveyn ayrılığı, yaş ve cinsiyet gibi çok hassas bir dizi kişisel özelliği otomatik ve doğru bir şekilde tahmin etmek için kullanılabilir. Sunulan analiz, Facebook beğenilerini, ayrıntılı demografik profillerini ve çeşitli psikometrik testlerin sonuçlarını sağlayan 58.000’den fazla gönüllüden oluşan bir veri kümesine dayanmaktadır. Önerilen model, beğeni verilerinin ön işlemesi için boyutluluk indirgeme kullanır, bu veriler daha sonra beğenilerden bireysel psikodemografik profilleri tahmin etmek için lojistik/doğrusal regresyona girilmektedir. Model, vakaların %88’inde eşcinsel ve heteroseksüel erkekleri, vakaların %95’inde Afrikalı Amerikalılar ve Kafkas Amerikalıları ve vakaların %85’inde Demokrat ve Cumhuriyetçi arasında doğru bir şekilde ayrım yapmaktadır. “Açıklık” kişilik özelliği için tahmin doğruluğu, standart bir kişilik testinin test-tekrar test doğruluğuna yakındır.
Beğenilerin Tahmin Gücü
Bireysel özellikler ve nitelikler, kullanıcıların beğeni kayıtlarına dayalı olarak yüksek derecede doğrulukla tahmin edilebilir. Örneğin, yüksek zekânın en iyi tahminleyicileri arasında “Fırtınalar”, “Colbert Raporu”, “Bilim” ve “Kıvırcık Patates” bulunurken, düşük zekâ “Sephora”, “Anne Olmayı Seviyorum”, “Harley Davidson” ve “Lady Antebellum” ile ilişkilendirilmiştir. Erkek eşcinselliğinin iyi belirleyicileri arasında “No H8 Campaign”, “Mac Cosmetics” ve “Wicked The Musical” yer alırken, erkek heteroseksüelliğinin güçlü belirleyicileri arasında “Wu-Tang Clan”, “Shaq” ve “Şekerleme Yapıp Uyandıktan Sonra Kafası Karışık Olmak” yer almaktadır. Bazı Beğeniler, No H8 Campaign ve eşcinsellik durumunda olduğu gibi, tahmin edilen nitelikler ile açıkça ilişkili olsa da diğer çiftler daha zor; örneğin Kıvırcık Patates Kızartmaları ile yüksek zekâ arasında bariz bir bağlantı yoktur.
Ayrıca, birkaç kullanıcının, niteliklerini açıkça ortaya koyan beğenilerle ilişkilendirildiğini unutmamak gerekir. Örneğin, eşcinsel olarak etiketlenen kullanıcıların %5’inden daha azı, No H8 Campaign, “Eşcinsel Olmak”, “Eşcinsel Evlilik”, “Eşcinsel Olmayı Seviyorum”, “Eşcinsel Olmayı Seçmedik, Seçildik” gibi açıkça eşcinsel olan gruplarla bağlantılıydı. Sonuç olarak, tahminler “Britney Spears” veya “Desperate Housewives” seçimleri (her ikisi de orta derecede eşcinsel olduğunu gösterir) gibi daha az bilgilendirici ama daha popüler beğenilere dayanmaktadır.
Bu, size Büyük Veri’nin eylem halinde olduğunu gösterecek küçük bir yapboz parçasıdır. Bir kişi hakkında birazcık bilgi aslında çok şey ortaya çıkarabiliyorsa, o zaman bunu insanların her gün ürettikleri tonlarca başka veriyle çarpın. Bunların ardından, bu veriler işlenilmeye başlanır. Facebook, insanları siyasi görüşler gibi kategorilere ayırmaktadır. 2016’da New York Times, “Herhangi bir adayın sayfalarını beğenmeseniz bile, sizinle aynı sayfaları beğenen insanların çoğu – Ben ve Jerry’nin dondurması gibi – kendini liberal olarak tanımlarsa, o zaman Facebook sizi de onlardan biri olarak sınıflandırabilir.” iddiasını ortaya koymuştur. Bunu biraz daha açacak olursak, eğer siz muhafazakâr birinin beğendiği paylaşımları veya resimleri beğeniyorsanız sizi de muhafazakâr olarak tanımlayabilirler. Ya da siyasette muhalif oldukları bilinen kişilerin sosyal medyadaki etkileşimlerine benzer etkileşimler yapıyorsanız sizi muhalif olarak tanımlayabilirler.
Bunun gibi kategoriler, Facebook’a reklam verenlerin çok özel kriterler seçmesine ve tam olarak onları görmek istedikleri insan gruplarına reklam göndermesine olanak tanır. Örneğin, 2016 ABD başkanlık kampanyası finansmanına ilişkin, Trump kampanyasının, Clinton karşıtı reklamları sosyal medyada görmek için belirli Hillary Clinton destekçi gruplarını seçtiğini ve bu grupların oy kullanma olasılıklarını düşürmeye çalıştığını kaydetmiştir.
 2018 Nisan ayında Facebook 87 milyon kullanıcının verilerinin yasal olmayan bir şekilde kopyalandığını ve Başkan Trump’ın 2016’daki seçim kampanyasında kullandığı ile ilgili açıklamada bulunmak zorunda kaldı. Bunu takiben gerek Amerika’da gerekse de Avrupa Birliğinde veri güvenliği konusunda ciddi endişeler dile gelmeye başladı. O zamana kadar aslında büyük verinin bu derece önemli olduğu ve bir ülkenin kaderini ne derecede etkileyebileceği tam anlaşılmamıştı. Bu skandaldan sonra veri güvenliği konusunda ciddi endişeler dile getirilmeye başlamıştır.
2018 Nisan ayında Facebook 87 milyon kullanıcının verilerinin yasal olmayan bir şekilde kopyalandığını ve Başkan Trump’ın 2016’daki seçim kampanyasında kullandığı ile ilgili açıklamada bulunmak zorunda kaldı. Bunu takiben gerek Amerika’da gerekse de Avrupa Birliğinde veri güvenliği konusunda ciddi endişeler dile gelmeye başladı. O zamana kadar aslında büyük verinin bu derece önemli olduğu ve bir ülkenin kaderini ne derecede etkileyebileceği tam anlaşılmamıştı. Bu skandaldan sonra veri güvenliği konusunda ciddi endişeler dile getirilmeye başlamıştır.
2018 yılının Mayıs ve Temmuz ayları arasında Amerika Planlı Ebeveynlik Federasyonu, Facebook’ta ABD’deki siyasi reklam harcamalarında Trump Amerika’yı Yeniden Büyük Bir Ülke Yapar Komitesi’nden sonra ikinci sırada yer almış, Amerika Planlı Ebeveynlik sözcüsü, New York Times gazetesine şöyle demiştir “Facebook’a reklam vermek hem 2,4 milyon hastamıza hem de 12 milyon destekçimize ulaşmanın uygun maliyetli yolu.” Hedef bazlı reklamlarda kullanılan algoritmalar ile kullanıcılar bazı özelliklerine göre kümelenir ve bu kümelemeye bağlı olarak istenilen gruba hitap edilmesi sağlanabilir. Örnek vermek gerekirse, sigara kullanmayan bir insana sigaranın sağlığa zararlarını anlatan bir reklam göstermek sadece kaynak israfıdır, haliyle sigara kullanan kullanıcılara bu gibi reklamları göstermek maliyet açısından çok avantajlıdır.
Büyük Verinin hayatınızı olumlu yönde etkilemesi için pek çok nokta mevcuttur. Büyük Veri, tıbbı kişiselleştirmek, hava durumunu tahmin etmek ve sürücüsüz arabalar yaratmak için kullanılır. Google Haritalar’ı her kullandığınızda Büyük Veri’yi de kullanıyorsunuz. Telefonunuzda konumunuzu etkinleştirdiyseniz, konumunuz ve hızınız hakkındaki bilgiler sürekli olarak Google’a geri gönderilir. Bu bilgi tek başına hiç kimse için çok yararlı değildir. Ancak çevrenizdeki sayısız insan da Google Haritalar’ı kullanmaktadır. Dolayısıyla Google, insanların nerede oldukları ve ne kadar hızlı hareket ettikleri hakkında tonlarca veriye sahiptir. Hatta bir Android kullanıcısıysanız muhtemelen işe gidiş geliş saatlerinize göre size trafiğin ne durumda olduğunu gösteren bilgilendirmeler geliyordur. Çünkü Google sizin saat kaçta işten çıktığınızı, nereye gideceğinizi, hangi rota üzerinden gideceğinizi öğrenmiş durumdadır. Bunu diğer kullanıcıların verile ile harmanlayarak bölgedeki trafik yoğunluğunu ölçümleyebilmektedir. Sonuçta tek yapması gereken arabada olan birinin kaç km/saat hız ile ilerlediğini hesaplamak ve buna bağlı olarak trafik sıkışıklığını tahminlemek. Böylece, tüm verileriyle, belirli bir yolda çok fazla trafik olup olmadığını uygulama vasıtasıyla görebilirsiniz. 2013’te Google, Waze uygulamasını satın aldı ve bu da onlara çalışmak için daha fazla veri sağlamıştır. Waze kullanıcıları, trafik ve kazaları gördüklerinde uygulamaya bildirmektedir. Dolayısıyla, Google Haritalar uygulamanız da bu verileri eş zamanlı olarak kullanır. Ayrıca kişisel geçmişinizi de takip ederek rotanızı sizi sabahları en rahat şekilde işe gidip gelmeniz için hazırlayabilir.
2016 yılında Çin’in Hangzhou kentinde uygulamaya konulan City Brain sistemi, bu konsepti bir adım öteye taşımaktadır. City Brain’in amacı, şehirdeki trafiği en aza indirmektir. Ayrıca, Google Haritalar gibi, Alibaba adında büyük bir perakendeci olan bir şirket tarafından yönetilmektedir. Aradaki fark şudur: şirket yerel yönetimden de yardım almaktadır. Böylece, City Brain Yapay Zekâ sistemi, verileri Google Haritalar’a benzer şekillerde almaktadır. Ancak ulaşım bürosundan ve şehir güvenlik kameralarından gelen bilgilere de erişimleri mevcuttur. Alibaba, 100’den fazla kavşağı kontrol etme yetkisinin kendilerine verildiği bir alanda trafik hızını %15 artırabildiklerini iddia etmiştir ve bunlar iki yönlü yollardır. Şehir ayrıca bu bilgilere erişimlerini kazaların nerede olduğunu görmek, acil durum araçları için yol tarifi almak ve altyapı değişikliği gerektiren alanları belirlemek için de kullanıyor. 2018’de City Brain’in ikinci bir şehirde, Kuala Lumpur, Malezya’da uygulanacağı açıklandı.
Netflix, eğlence deneyiminizi geliştirmek için “Büyük Veri” kullanmaktadır. Öneriler vermek gerekirse, Netflix’in algoritması, Matt Damon’ın oynadığı filmleri sevdiğinizi, tıklamalar ve izlenme süresi hakkındaki sonsuz bir veri akışından öğrenir.
Büyük Veri, bir dizi veya film için izleyeceğiniz görüntüyü de etkilemektedir. Örneğin, Netflix dizisi Stranger Things için gösterebileceğiniz bazı resimlere bakalım. Netflix, hangi görseli göreceğinize karar vermek için elindeki tüm verileri kullanır.

Başlık ve resim kategorisinde, içeriğe ilk kez maruz kaldığınızdan dolayı, size çekici gelen bir resim seçmek, onu izleme kararınızı etkileyebilir. Örneğin Good Will Hunting filmini ele alalım. Netflix Tech Blog’daki bu gönderi, geçmiş izleme alışkanlıklarınızın hangi görüntüyü alacağınızı nasıl etkileyebileceğini göstermektedir. Hevesli bir romantizm filmi veya dizisi izleyicisiyseniz, Matt Damon ve Minnie Driver’ın öpüştüğü bir resme daha çok ilgi duyabilirsiniz. Ancak bir sürü komedi izliyorsanız, Robin Williams sizi izlemeye ikna etmek için yeterli olabilir.

Netflix bunu her film için yapmaktadır. Elindeki büyük miktarda veriyi kullanmak, Netflix’in sizin izleme deneyiminizi daha iyi hale getirmesini sağlamaktadır.
Siyasette Büyük Veri Kullanımı
Siyaset alanında büyük verinin kullanım alanına da değinmek gerekiyor çünkü birçok siyasi figür bu konuda sadece bazı anket firmaları ile çalışmakta ve onların sunduğu veriler üzerinden hareket etmektedir. Toplumun nabzının tutulabileceği en iyi ölçümün anketler olduğunu düşünmektedir. Fakat bu artık geçerliliğini yitirmiş bir argüman olmaktadır.
Google Trends (Google Arama Trendleri) Ocak 2022 sonu itibari ile muhalefet partilerinin kendi aralarındaki arama trendlerine bakılabilir. Bu bize liderlerin popülaritelerinin veya başka bir değişle gündemdeki popülerliklerinin değişimlerini göstermektedir. Aşağıdaki tabloda görüldüğü üzere İYİ Parti Lideri Meral Akşener’in son 1 yıl içerisindeki popülaritesi azalmaktayken CHP Lideri Kılıçdaroğlu, DEVA Partisi Lideri Ali Babacan ve Saadet Partisi Lideri Temel Karamollaoğlu’nun popülaritesinin artmakta olduğunu gözlemleyebiliriz.

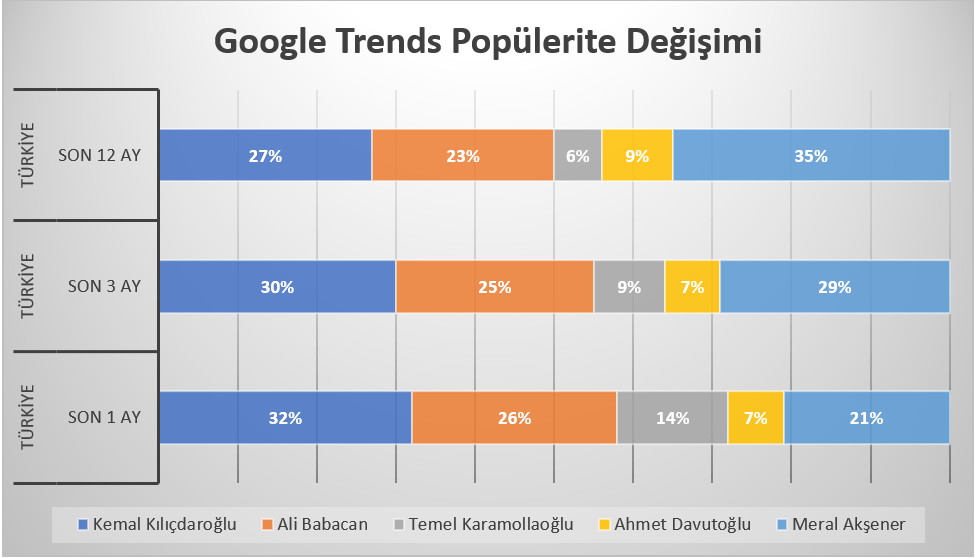
Google Trends bizlere açık kaynak olarak bu verile sunmaktadır. Fakat aynı anda beş karşılaştırma yapılabildiğinden bazı sınırlamalara tabi olmaktadır. Ama paralı olarak bu hizmet satın alınmak istenildiğinde ulaşılabilecek veriler ile yapılabilecek tahminlemenin ucu bucağı yoktur.
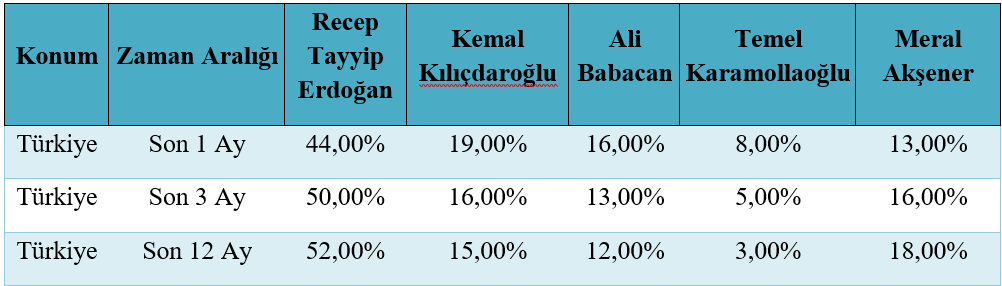
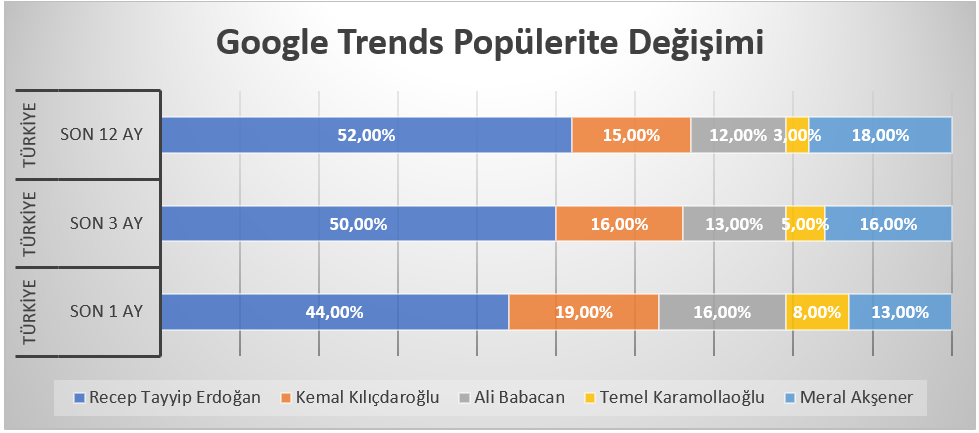
Yukarıdaki grafikler oy oranları olarak değerlendirmemek lazım. Fakat gündemdeki yerlerini göstermek açısından güzel bir indikatör olarak kullanılabilir. Google’daki aramalarda ne kadar çok hakkında arama olursa insanlar o kadar merak ediyor anlamına gelir. Popülaritedeki azalma ve artma insanları sizin söylemleriniz ile ilgilenmediği veya çok merak ettikleri ve gündemi yönlendirebildiğiniz algısını öne çıkartmamaktadır.
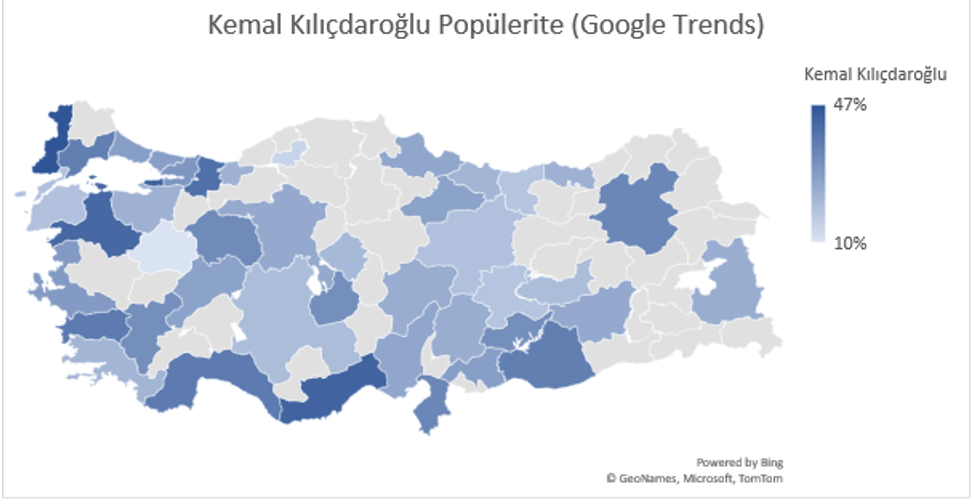
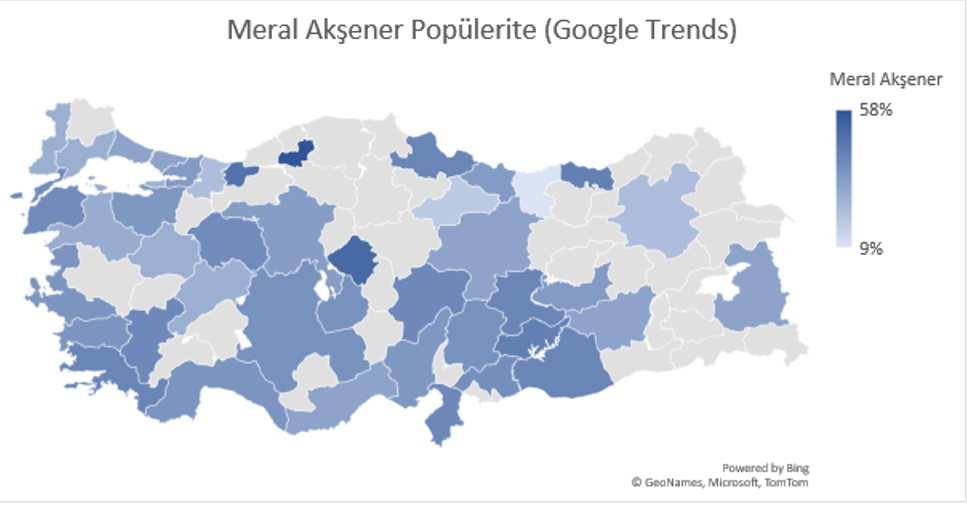
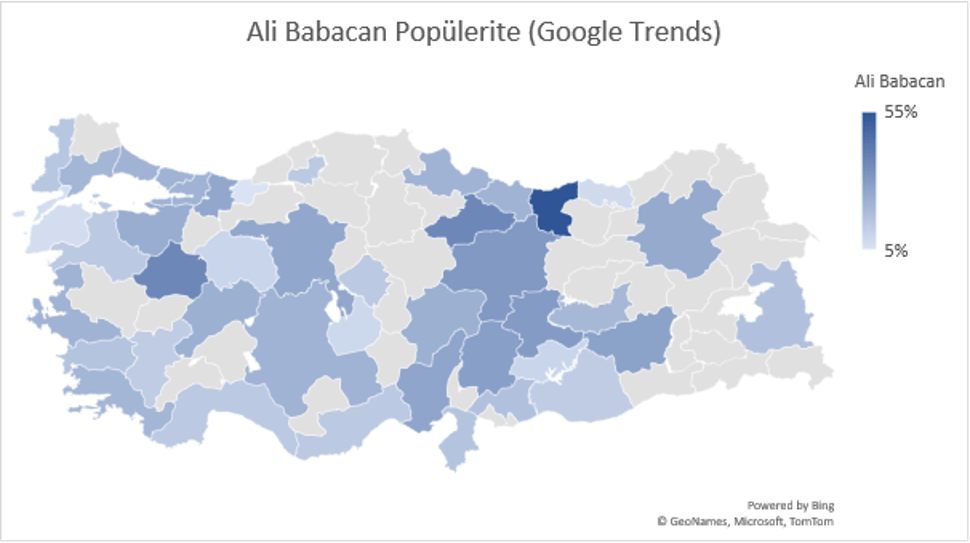
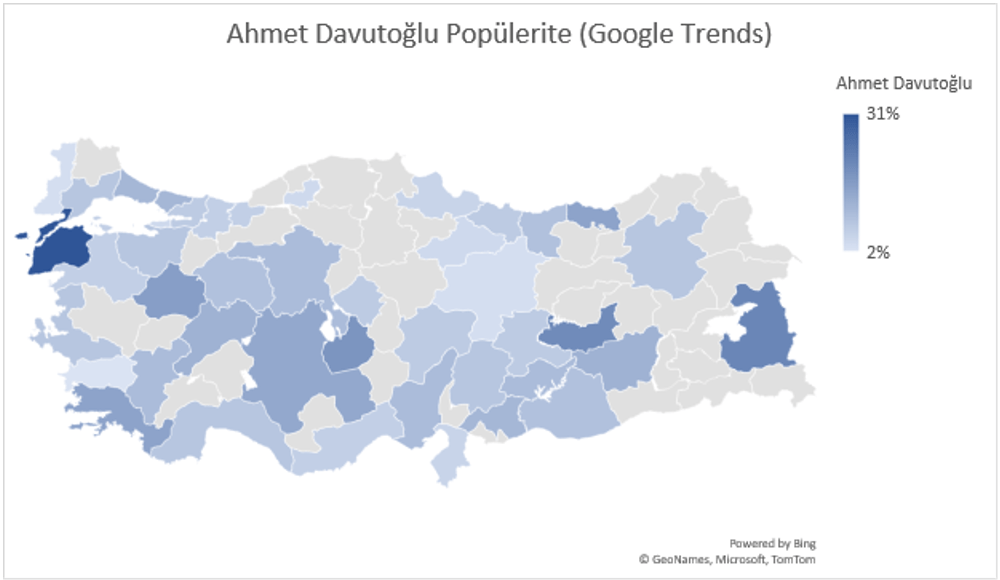
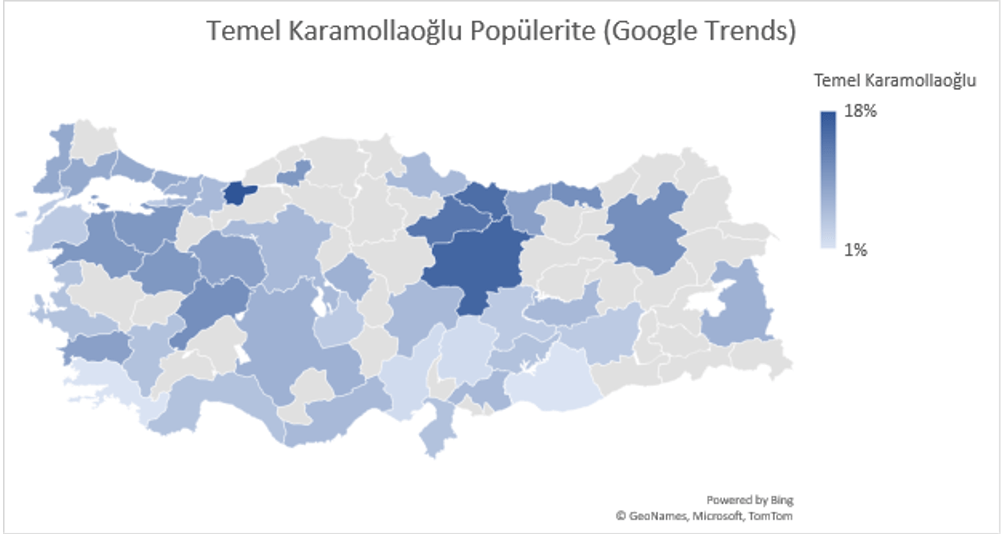
Yukarıdaki beş harita liderlerin popülaritelerinin şehirlere göre dağılımında kendi aralarındaki popülerlik farkını göstermektedir. Bazı şehirlerde Temel Karamollaoğlu popüler iken bazı şehirlerde Ali Babacan bazılarında ise Meral Akşener’in popüler olduğu gözlemlenmektedir. Seçim kampanyaları veya aday dağılımlarının bu gibi faktörler göz önüne alınarak yapılması büyük verinin kullanımı açısından daha isabetli sonuçlar doğurabilir.
Google Trends Son 12 Aylık Arama Sonuçları Dağılımı
| İller | Kemal Kılıçdaroğlu | Ali Babacan | Temel Karamollaoğlu | Ahmet Davutoğlu | Meral Akşener |
| Adana | 26% | 27% | 2% | 10% | 35% |
| Adıyaman | 32% | 10% | 5% | 10% | 43% |
| Afyonkarahisar | 27% | 23% | 11% | 12% | 27% |
| Aksaray | 32% | 9% | 4% | 18% | 37% |
| Ankara | 25% | 26% | 6% | 10% | 33% |
| Antalya | 37% | 14% | 5% | 8% | 36% |
| Aydın | 37% | 16% | 9% | 2% | 36% |
| Balıkesir | 42% | 14% | 10% | 6% | 28% |
| Bursa | 23% | 24% | 10% | 8% | 35% |
| Denizli | 32% | 13% | 5% | 10% | 40% |
| Diyarbakır | 25% | 28% | 4% | 12% | 31% |
| Düzce | 23% | 5% | 18% | 6% | 48% |
| Edirne | 47% | 15% | 8% | 3% | 27% |
| Elazığ | 20% | 20% | 6% | 20% | 34% |
| Erzurum | 34% | 25% | 11% | 8% | 22% |
| Eskişehir | 33% | 10% | 9% | 9% | 39% |
| Gaziantep | 28% | 17% | 6% | 11% | 38% |
| Giresun | 18% | 55% | 9% | 9% | 9% |
| Hatay | 34% | 16% | 5% | 5% | 40% |
| Kahramanmaraş | 24% | 29% | 2% | 8% | 37% |
| Karabük | 14% | 14% | 10% | 4% | 58% |
| Kayseri | 24% | 23% | 6% | 7% | 40% |
| Kocaeli | 30% | 22% | 7% | 7% | 34% |
| Konya | 20% | 22% | 7% | 14% | 37% |
| Kütahya | 10% | 37% | 10% | 16% | 27% |
| Kırşehir | 21% | 14% | 7% | 7% | 51% |
| Malatya | 18% | 30% | 4% | 7% | 41% |
| Mersin | 43% | 14% | 6% | 6% | 31% |
| Muğla | 22% | 21% | 1% | 15% | 41% |
| Ordu | 22% | 22% | 15% | 7% | 34% |
| Sakarya | 40% | 26% | 6% | 6% | 22% |
| Samsun | 26% | 22% | 6% | 5% | 41% |
| Sivas | 19% | 31% | 16% | 3% | 31% |
| Tekirdağ | 36% | 21% | 8% | 8% | 27% |
| Tokat | 27% | 37% | 14% | 4% | 18% |
| Trabzon | 23% | 8% | 11% | 15% | 43% |
| Van | 24% | 17% | 7% | 21% | 31% |
| Yalova | 44% | 22% | 4% | 4% | 26% |
| Çanakkale | 19% | 7% | 4% | 31% | 39% |
| İstanbul | 28% | 22% | 8% | 11% | 31% |
| İzmir | 29% | 22% | 5% | 8% | 36% |
| Şanlıurfa | 36% | 13% | 1% | 9% | 41% |
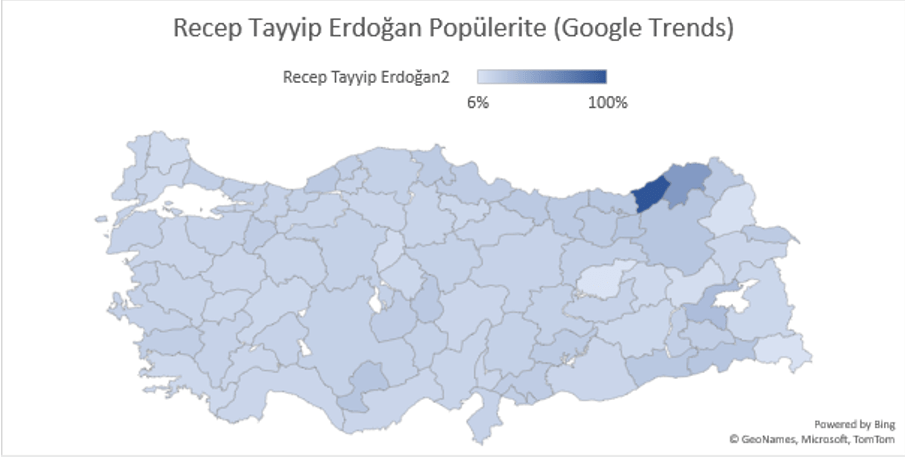
Yukardaki haritada Cumhurbaşkanı Recep Tayyip Erdoğan’ın Google trends verilerine dayanarak popülerliğinin nasıl illere göre dağıldığı gözlemlenmektedir. Aşağıdaki haritada Cumhurbaşkanı Erdoğan’ın mutlak popülarite gücü Rize’de gözükmektedir. Fakat daha bir analiz için daha alt sekmelere ayırmak gerekmekte. Fakat bu yazımızın amacı büyük verinin kullanım yöntemlerini ve hayatımızda ne derece önemli bir yeri olduğunu göstermek olduğu için Google Trends ile ilgili bu basit örnekleri burada noktalıyoruz.
Sonuç
Büyük veri artık hayatımızın bir parçası haline gelmiştir. Büyük verinin saklanması ve sonrasında işlenmesi gerek hükümetler gerekse de özel şirketler açısından çok büyük önem arz etmektedir. Büyük veri sayesinde kitlelerin isteklerini, davranışlarını, sağlık durumlarını, harcama alışkanlıklarını, siyasi görüşlerini doğru ve kolay bir şekilde analiz edebilir ve hatta yönlendirebilirsiniz.
Büyük verinin saklanması kadar, işlenebilir olması da önemlidir. Verileri yer altı madenlerimiz gibi düşlenebilirsiniz. Eğer o verileri işleyemezseniz sadece yer kaplarlar. Günümüz Türkiye’sinde veri işleme konusunda her ne kadar özel şirketler öncülük yapsa da devletin de bu konuda teknik altyapı sunabiliyor olması lazımdır. Türkiye’deki verilerin işlenmesi için genellikle Amazon, Google veya IBM gibi dış kaynaklar kullanmaktadır. Amerika ve Çin arasındaki süregelen sürtüşmelerin büyük bir kısmı da bu büyük veri kavgasından kaynaklanmaktadır. Özellikle Huawei ile ilgili olan mahkeme süreçleri bu şekildedir.
Türkiye’nin ise acilen verileri Türkiye’de işleyebileceğimiz büyük veri saklama ve işleme merkezleri kurması gerekmektedir. Büyük veriyi ne kadar iyi saklayıp analiz edebilirseniz tahminlime gücünüz o kadar yükselmektedir. Büyük veri sayesinde, bir kalem üründe yapacağınız vergi artışının kullanıcı harcamalarındaki etkisini ve diğer kalemlere olan etkisini gözlemleyebilir, daha doğru bir devlet politikası belirleyebilirsiniz. Ama bunların hepsi için gerekli altyapının hazırlanması gerekmektedir.
Buna ek olarak da verileri analiz edebilecek teknik elemanların yetiştirilmesi ve beyin göçünün bu konuda durdurulması gerekiyor. Büyük veri üzerine çalışanlar yurt dışında çok rahatlıkla iş bulabildikleri ve genellikle sadece İngilizce yeterli olduğundan dolayı, bu alanda Türkiye çok fazla beyin göçü vermektedir. Bunun önüne mutlaka geçilmesi gerekmektedir. Yoksa veriyi saklamak için çıkardığımız kanunlar ile bir yere varmamız mümkün değildir. O veriyi işleyecek beyin gücü yoksa sadece bitlerden (1 ve 0’lar) ibaret bir verinin hiçbir değeri yoktur.
Kaynakça
Private traits and attributes are predictable from digital records of human behavior | PNAS
Liberal, Moderate or Conservative? See How Facebook Labels You – The New York Times (nytimes.com)
The Biggest Spender of Political Ads on Facebook? President Trump – The New York Times (nytimes.com)
Artwork Personalization at Netflix | by Netflix Technology Blog | Netflix TechBlog
https://cra.org/ccc/wp-content/uploads/sites/2/2015/05/Big_Data.pdf